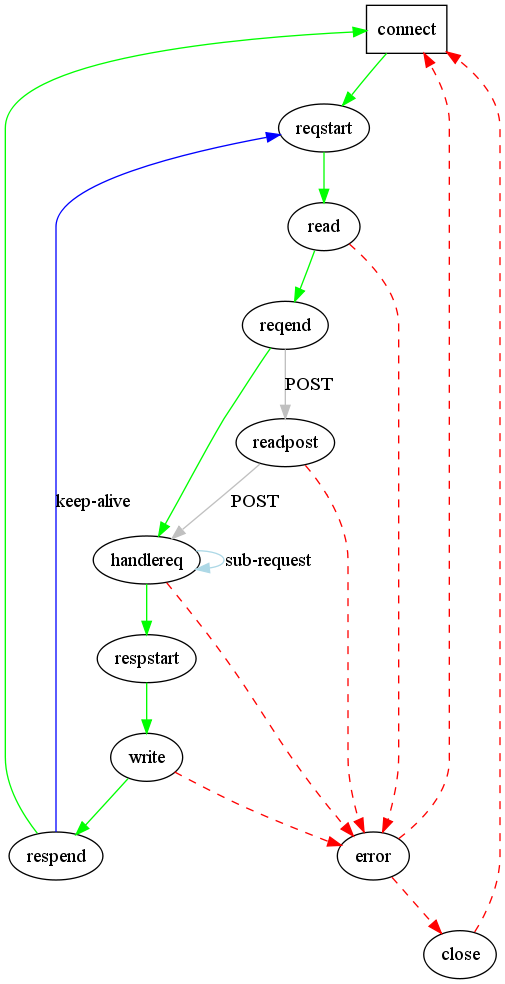
wifidog认证自带http服务器Lighttpd1.4.20源码分析之状态机(3)返回response
好久没顾这个了,最近比较清闲,重新拾掇一下,有始有终。
回到正题,前一篇介绍完了请求的处理,先面lighttpd将会把处理的结果返回给客户端。状态机进入CON_STATE_RESPONST_START。在这个状态中,服务器主要的工作在函数connection_handle_write_prepare。这个函数不算复杂,主要是根据客户端请求的method来设置response的headers,其实就是设置“Content-Length”的值。下面是函数代码,做了一些删减:
static int connection_handle_write_prepare(server * srv, connection * con)
{
if (con->mode == DIRECT)
{
/*
* static files
*/
switch (con->request.http_method)
{
case HTTP_METHOD_GET:
case HTTP_METHOD_POST:
case HTTP_METHOD_HEAD:
case HTTP_METHOD_PUT:
case HTTP_METHOD_MKCOL:
case HTTP_METHOD_DELETE:
case HTTP_METHOD_COPY:
case HTTP_METHOD_MOVE:
case HTTP_METHOD_PROPFIND:
case HTTP_METHOD_PROPPATCH:
case HTTP_METHOD_LOCK:
case HTTP_METHOD_UNLOCK:
break;
case HTTP_METHOD_OPTIONS:
/*
* 400 is coming from the request-parser BEFORE uri.path is set
* 403 is from the response handler when noone else catched it
* */
if ((!con->http_status || con->http_status == 200)
&& con->uri.path->used && con->uri.path->ptr[0] != '*')
{
response_header_insert(srv, con, CONST_STR_LEN("Allow"),
CONST_STR_LEN("OPTIONS, GET, HEAD, POST"));
con->response.transfer_encoding &= ~HTTP_TRANSFER_ENCODING_CHUNKED;
con->parsed_response &= ~HTTP_CONTENT_LENGTH;
con->http_status = 200;
con->file_finished = 1;
chunkqueue_reset(con->write_queue);
}
break;
default:
switch (con->http_status)
{
case 400: /* bad request */
case 414: /* overload request header */
case 505: /* unknown protocol */
case 207: /* this was webdav */
break;
default:
con->http_status = 501;
break;
}
break;
}
}
if (con->http_status == 0)
{
con->http_status = 403;
}
switch (con->http_status)
{
case 204: /* class: header only */
case 205:
case 304:
/*
* disable chunked encoding again as we have no body
*/
con->response.transfer_encoding &= ~HTTP_TRANSFER_ENCODING_CHUNKED;
con->parsed_response &= ~HTTP_CONTENT_LENGTH;
chunkqueue_reset(con->write_queue);
con->file_finished = 1;
break;
default: /* class: header + body */
if (con->mode != DIRECT)
break;
/*
* only custom body for 4xx and 5xx
*/
if (con->http_status < 400 || con->http_status >= 600)
break;
con->file_finished = 0;
buffer_reset(con->physical.path);
/*
* try to send static errorfile
*/
if (!buffer_is_empty(con->conf.errorfile_prefix))
{
//设置对应的错误提示文件
}
if (!con->file_finished)
{
//没有对应的错误提示文件,设置默认错误提示。
}
break;
}
if (con->file_finished)
{
/*
* we have all the content and chunked encoding is not used, set a
* content-length
*/
if ((!(con->parsed_response & HTTP_CONTENT_LENGTH)) &&
(con->response.transfer_encoding & HTTP_TRANSFER_ENCODING_CHUNKED) == 0)
{
off_t qlen = chunkqueue_length(con->write_queue);
/**
* The Content-Length header only can be sent if we have content:
* - HEAD doesn't have a content-body (but have a content-length)
* - 1xx, 204 and 304 don't have a content-body (RFC 2616 Section 4.3)
*
* Otherwise generate a Content-Length header as chunked encoding is not
* available
*/
if ((con->http_status >= 100 && con->http_status < 200) ||
con->http_status == 204 || con->http_status == 304)
{
data_string *ds;
/*
* no Content-Body, no Content-Length
*/
if (NULL != (ds = (data_string *) array_get_element(con->response.headers, "Content-Length")))
{
buffer_reset(ds->value); /* Headers with empty values
* are ignored for output */
}
}
else if (qlen > 0 || con->request.http_method != HTTP_METHOD_HEAD)
{
/*
* qlen = 0 is important for Redirects (301, ...) as they MAY
* have a content. Browsers are waiting for a Content otherwise
*/
buffer_copy_off_t(srv->tmp_buf, qlen);
response_header_overwrite(srv, con, CONST_STR_LEN("Content-Length"), CONST_BUF_LEN(srv->tmp_buf));
}
}
}
else
{
/**
* the file isn't finished yet, but we have all headers
*
* to get keep-alive we either need:
* - Content-Length: ... (HTTP/1.0 and HTTP/1.0) or
* - Transfer-Encoding: chunked (HTTP/1.1)
*/
if (((con->parsed_response & HTTP_CONTENT_LENGTH) == 0) &&
((con->response.transfer_encoding & HTTP_TRANSFER_ENCODING_CHUNKED) == 0))
{
con->keep_alive = 0;
}
/**
* if the backend sent a Connection: close, follow the wish
*
* NOTE: if the backend sent Connection: Keep-Alive, but no Content-Length, we
* will close the connection. That's fine. We can always decide the close
* the connection
*
* FIXME: to be nice we should remove the Connection: ...
*/
if (con->parsed_response & HTTP_CONNECTION)
{
/*
* a subrequest disable keep-alive although the client wanted it
*/
if (con->keep_alive && !con->response.keep_alive)
{
con->keep_alive = 0;
}
}
}
if (con->request.http_method == HTTP_METHOD_HEAD)
{
/**
* a HEAD request has the same as a GET
* without the content
*/
con->file_finished = 1;
chunkqueue_reset(con->write_queue);
con->response.transfer_encoding &= ~HTTP_TRANSFER_ENCODING_CHUNKED;
}
http_response_write_header(srv, con);
return 0;
}
首先,该函数判断连接的模式(mode)是否是DIRECT,如果是,说明连接没有经过插件处理,是由服务器自身处理的。这里判断连接的请求method,如果是OPTION,则设置Allow的值。同时清空write_queue,因为没有数据需要返回。 接着,在下面这个switch语句中,比较http_status的值,如果为204,205,304,说明服务器不需要给客户端返回文件,仅仅返回 response中headers及其之前的部分。这里和前面处理OPTION方法都设置con->file_finished为1。 file_finished用来标记客户端请求的静态文件是否已经发送完了(这个file_finished的含义比较模糊,目前还没搞清楚是表示文件发 送完毕,还是要发送的文件设置完毕可以发送。。。也有可能是个bug。。。如果各位读者有什么高见,还望不吝赐教!)。这两处都不需要给客户端发送文件, 因此将其设置为1,发送程序将直接跳过文件的发送。switch的default分支处理4xx错误,返回相应的错误提示文件。
出了switch语句之后,接着是一个if判断file_finished的值。如果值为1,说明不需要给客户端返回文件数据。对于1xx,204和 304状态,将Content-Length设置为空值。如果method是HEAD,那么服务器可能需要返回一些数据,这时候要设置对应的 Content-Length。如果file_finished的值为0,那么要设置一下keep_alive的值。在 connection_handle_write_prepare函数的最后,调用http_response_write_header将 headers写入write_queue,等待返回给客户端。如果一切顺利,那么状态机进入CON_STATE_WRITE。
由于数据可能不会一次写完,尤其是发送大文件的时候。因此,在CON_STATE_WRITE状态中首先判断write_queue时候为空,也就是有没 有数据还没有发送。同时判断连接是否可写。如果有数据且可写,那么调用connection_handle_write发送数据。如果没有数据可写或者连 接不可写,那么会退出switch(con->state)这个语句。同时,由于状态机状态没有发生改变,switch后面的if语句使得服务器退 出了大while循环,进入循环后面的小switch(con->state)语句。这个switch语句在前面已经介绍过。在这里,进入 CON_STATE_WRITE分支,如果有数据可写且连接可写且没有达到流量限制,那么在fdevent中注册这个连接,否则,删除这个连接。
下面我们进入connection_handle_write函数,看看有数据可写且连接可写的情况。connection_handle_write函 数会首先在switch语句中调用network_write_chunkqueue函数。顾名思义,这个函数就是将write_queue中的数据写回 给客户端的。函数network_write_chunkqueue首先判断当前连接的流量是否超过了限制,如果是,则不发送任何数据,直接将连接加到作 业列表(joblist)中,让其他连接发送数据。如果没有超限,那么首先设置TCP_CORK选项。这个选项可以将多个write调用的数据一起发送, 提高发送效率。有关TCP_CORK的内容读者可自行google之。接下来就是调用srv->network_backend_wirte()函 数进行真正的写数据了。这个函数的真正定义有多个,在network_*.c文件中。服务器在network.c的network_init函数中会根据 当前的运行环境设置不同的值。为了提高服务器的效率,不同的OS会提供一些不同的方法,提高发送文件的速度。通过传统的先read在write的方法,需 要4次数据拷贝(从磁盘到内核缓冲区,从内核缓冲区到用户缓冲区,从用户缓冲区到网络接口的内核缓冲区,最后,从网络接口的内核缓冲区到网络设备缓冲 区。),OS会提供一些特定的方法来减少拷贝的次数,具体读者可以google“直接IO”,有不少介绍这个的文章。为了充分利用这些方法来提高服务器的 性能,lighttpd在不同的OS上都会去使用这些特定的接口,因此就需要多个network_backend_wirte函数的实现。这些实现基本上 大同小异,因此这里只介绍network_write.c中的实现。函数的主体是个大循环,遍历所有的chunk。如果chunk的类型是 MEM_CHUNK,那么这个chunk中的数据是在内存中的,直接调用write或者windows下的send函数发送数据。如果是 FILE_CHUNK类型,说明这个chunk表示的是一个文件,那么如果运行环境有mmap函数,就使用mmap映射文件并发送,否则就read在 write。如果这个chunk发送完了,那么继续发送下一个chunk。如果没有发送完(chunk_finished=0),那么退出循环,接着也就 退出了这个函数。服务器这时返回到network_write_chunkqueue中,下面做一些统计工作,再一次检查该连接的流量是否超限。最后服务 器返回到connection_handle_write中。如果network_write_chunkqueue返回-1,表示服务器出错。状态机进 入CON_STATE_ERROR。如果返回-2,则客户端关闭连接,状态机也进入CON_STATE_ERROR。返回0表示发送完毕,进入下一个状 态。返回1说明数据没有发送完,标记is_wirtable为0。
从connection_handler_write函数返回后,如果数据没有发送完毕,那么状态机还在
CON_STATE_WRITE状态,接着连接被加到fdevent系统中,等待下一次数据发送。重复上述过程知道发送完毕或出错。
如果数据发送完毕,状态机进入CON_STATE_RESPONSE_END状态。在这个状态中,服务器首先调用 plugins_call_handle_request_done通知所有插件连接处理完毕。然后判断是否保持连接,如果保持,将状态机设置为 CON_STATE_REQUEST_START。如果不保持,那么先调用plugins_call_handle_connection_close通 知所有插件连接关闭。然后关闭连接。最后,重置con,清除前一次请求的数据。
至此,请求处理结束。总的来说,返回response的过程还算直接,没有多少难懂的地方。比较不好懂的地方都是关于http协议中一些情况的细节处理,读者可以参照rfc理解。
下面一片文章将会分析一些错误处理过程。
本文章由 http://www.wifidog.pro/2015/04/10/wifidog%E8%AE%A4%E8%AF%81lighttpd-1.html 整理编辑,转载请注明出处