wifidog源码分析Lighttpd1.4.20源码分析之fdevent系统(1)---fdevents结构体和fdevent系统对外接口
前面讲了lighttpd的插件系统,这一篇将看一看lighttpd中的fdevent系统。fdevent系统主要是处理各种IO事件,在web服务器中,主要就是向socket写数据和从socket读数据。通常,web服务器是IO密集型程序,这就要求在数据的读写上,web服务器必须能够具有很好的性能,不会因为某个socket的阻塞而致使其他socket也被阻塞,否则会大大降低服务器的性能。因此,大部分的web服务器都采用非阻塞IO进行数据的读写。lighttpd通过fdevent系统,采用类似OO中面向对象的方式将对IO事件的处理进行封装,对于不同的IO系统,提供一个统一的接口。
lighttpd采用了所谓的Reactor模式,也就是非阻塞IO加多路复用(non-blocking IO + IO multiplexing)。在多路复用上,lighttpd通过fdevent将各种不同的实现进行封装。lighttpd使用的多路IO有如下几个:
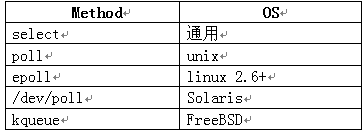
下面看一下fdevent.h中fdevents结构体,这个结构体相当于是一个虚基类,其中的函数指针是纯虚函数。对于每种实现,则相当于是继承了这个基类并实现了其中的纯虚函数,也就是给函数指针赋一个函数地址值。下面是代码:
typedef struct fdevents
{
fdevent_handler_t type; //多路IO类型
fdnode **fdarray; //文件描述符数组
size_t maxfds; //最大的文件描述符数
#ifdef USE_LINUX_SIGIO
int in_sigio;
int signum;
sigset_t sigset;
siginfo_t siginfo;
bitset *sigbset;
#endif
#ifdef USE_LINUX_EPOLL
int epoll_fd;
struct epoll_event *epoll_events;
#endif
#ifdef USE_POLL
struct pollfd *pollfds; //描述符及其状态的结构体数组
size_t size; //数组中数据的个数
size_t used; //数组的大小
//用于存储pollfds中为使用的位置。
//由于可能的删除操作,会是pollfds中存在空档,将这些空档
//的索引存在unused中,便于下次插入操作时直接使用这些空档
//减少空间的浪费。
buffer_int unused;
#endif
#ifdef USE_SELECT
//三个文件描述符集合
fd_set select_read; //可读,对应FDEVENT_IN
fd_set select_write; //可写,对应FDEVENT_OUT
fd_set select_error; //处于异常条件,对应FDEVENT_ERR
//由于select函数会修改上面的三个集合,
//因此,在这里保存一个初始的副本。
fd_set select_set_read;
fd_set select_set_write;
fd_set select_set_error;
int select_max_fd; //最大的文件描述符数。
#endif
#ifdef USE_SOLARIS_DEVPOLL
int devpoll_fd;
struct pollfd *devpollfds;
#endif
#ifdef USE_FREEBSD_KQUEUE
int kq_fd;
struct kevent *kq_results;
bitset *kq_bevents;
#endif
#ifdef USE_SOLARIS_PORT
int port_fd;
#endif
//统一的操作接口,与后面的函数声明对应。
int (*reset) (struct fdevents * ev);
void (*free) (struct fdevents * ev);
int (*event_add) (struct fdevents * ev, int fde_ndx, int fd, int events);
int (*event_del) (struct fdevents * ev, int fde_ndx, int fd);
int (*event_get_revent) (struct fdevents * ev, size_t ndx);
int (*event_get_fd) (struct fdevents * ev, size_t ndx);
int (*event_next_fdndx) (struct fdevents * ev, int ndx);
int (*poll) (struct fdevents * ev, int timeout_ms);
int (*fcntl_set) (struct fdevents * ev, int fd);
} fdevents;
可以看到这个结构体中使用很多宏,这是为了在编译的时候去掉那些没有使用到的变量,根据当前所使用的多路IO系统,对这个结构体进行定制。
结构体的第一个成员是一个枚举类型fdevent_handler_t,定义如下:
typedef enum
{
FDEVENT_HANDLER_UNSET, //未定义
FDEVENT_HANDLER_SELECT, //select
FDEVENT_HANDLER_POLL, //poll
FDEVENT_HANDLER_LINUX_RTSIG, //rtsig
FDEVENT_HANDLER_LINUX_SYSEPOLL, //sysepoll
FDEVENT_HANDLER_SOLARIS_DEVPOLL, //devpoll
FDEVENT_HANDLER_FREEBSD_KQUEUE, //kqueue
FDEVENT_HANDLER_SOLARIS_PORT //port
} fdevent_handler_t;
这个枚举类型标记了所有可能用到的多路IO系统。
结构体中的第二个成员fdnode **fdarray;,是一个fdnode类型变量的数组。fdnode的定义如下:
typedef struct _fdnode
{
fdevent_handler handler; //处理函数指针
void *ctx; //文件描述符的context
int fd; //文件描述符
struct _fdnode *prev, *next; //指针
} fdnode;
fdevent_handler handler是一个函数指针,用来存储这个描述符处理函数的地址。关于这个地址,后面的文章中将会有详细的介绍,其定义为typedef handler_t(*fdevent_handler) (void *srv, void *ctx, int revents);。从最后两个变量可以看出,这应该是一个链表的节点,但是,这个结构体是以数组的形式存储的,也就是fdevents中的fdarray变量,这样可以提高查询的效率。
后面由宏包裹的变量就是对于各个不同的多路IO系统定义的变量。我们着重看一看linux下的epoll所使用的变量:
#ifdef USE_LINUX_EPOLL
int epoll_fd; //epoll_create返回的描述符
struct epoll_event *epoll_events;//保存fd及对应的事件
#endif
这里要说明一下poll使用的变量buffer_init unused。这个变量的类型的定义如下:
typedef struct
{
int *ptr; //位置索引数组。
size_t used; //数组中数据个数。
size_t size; //数组长度。
} buffer_int;
其实就是一个int数组,只不过封装了一下,增加了两个属性。unused数组中存放的是pollfds的下标值。在后面的实现中我们可以看到,pollfds是一个struct pollfd类型数组,注意,不是这个类型的指针的数组。这个数组的大小是根据fdevents中的maxfds的值定的,并且在初始化的时候数组的空间也一次性分配好。由于对pollfds数组有删除元素的操作,因此,会在数组中留下“洞”,而ununsd就是存储这些“洞”的下标值,便于在插入元素时,快速的找到位置。这是一个很有用的技巧,在对数据进行反复的删除插入元素操作时,可以提高效率。大多数情况下使用栈链表来存储这些可用空间的下标,栈顶指向链表头。
其余的变量读者可自行分析。
接下来看看这些函数指针。这些函数指针对应与结构体定义后面的一系列函数声明。从名字中可以轻易的看出对应关系。
/*
* 重置和释放fdevent系统。
*/
int fdevent_reset(fdevents * ev);
void fdevent_free(fdevents * ev);
/*
* 将fd增加到fd event系统中。events是要对fd要监听的事件。
* fde_ndx是fd对应的fdnode在ev->fdarray中的下标值的指针。
* 如果fde_ndx==NULL,则表示在fd event系统中增加fd。如果不为NULL,则表示这个
* fd已经在系统中存在,这个函数的功能就变为将对fd监听的事件变为events。
*/
int fdevent_event_add(fdevents * ev, int *fde_ndx, int fd, int events);
/*
* 从fd event系统中删除fd。 fde_ndx的内容和上面的一致。
*/
int fdevent_event_del(fdevents * ev, int *fde_ndx, int fd);
/*
* 返回ndx对应的fd所发生的事件。
* 这里的ndx和上面的fde_ndx不一样,这个ndx是ev->epoll_events中epoll_event结构体的下标。
* 第一次调用的时候,通常ndx为-1。
* 这个ndx和其对应的fd没有关系。而fde_ndx等于其对应的fd。
*/
int fdevent_event_get_revent(fdevents * ev, size_t ndx);
/*
* 返回ndx对应的fd。
*/
int fdevent_event_get_fd(fdevents * ev, size_t ndx);
/*
* 返回下一个发生IO事件的fd。
*/
int fdevent_event_next_fdndx(fdevents * ev, int ndx);
/*
* 开始等待IO事件。timeout_ms是超时限制。
*/
int fdevent_poll(fdevents * ev, int timeout_ms);
/**
* 设置fd的状态,通常是设置为运行exec在子进程中关闭和非阻塞。
*/
int fdevent_fcntl_set(fdevents * ev, int fd);
在fdevent.c文件中,这些函数的实现基本上都是简单的调用fdevents结构体中对应的函数指针。对于lighttpd,通过调用上面的这些函数完成IO事件的处理,对于具体到底是谁处理了这些事件,lighttpd并不知道,也不关心。
剩下的函数声明:
/*
* 返回fd对应的事件处理函数地址。也就是fdnode中handler的值。
*/
fdevent_handler fdevent_get_handler(fdevents * ev, int fd);
/*
* 返回fd对应的环境。也就是fdnode中ctx的值。
*/
void *fdevent_get_context(fdevents * ev, int fd);
/*
* 注册和取消注册fd。
* 就是生成一个fdnode,然后保存在ev->fdarray中。或者删除之。
*/
int fdevent_register(fdevents * ev, int fd, fdevent_handler handler, void *ctx);
int fdevent_unregister(fdevents * ev, int fd);
/**
* 初始化各种多路IO。
*/
int fdevent_select_init(fdevents * ev);
int fdevent_poll_init(fdevents * ev);
int fdevent_linux_rtsig_init(fdevents * ev);
int fdevent_linux_sysepoll_init(fdevents * ev);
int fdevent_solaris_devpoll_init(fdevents * ev);
int fdevent_freebsd_kqueue_init(fdevents * ev);
下面总结一下:
文件fdevent.h中声明的一系列函数就是fdevent系统对外的接口,这相当与类的公有函数。lighttpd通过调用这些函数来实现IO事件的处理。在这些函数的具体实现仅仅是简单的调用了fdevents结构体中的函数指针。而这写函数指针所对应的函数分别定义在以fdevent_开头的.c文件中。从这些文件的名字可以看出其所对应的IO系统。在这些文件中,函数大多是static,这就行当与类的私有函数,起到隐藏具体实现的效果。后面的问装中我们会具体的分析一个多路IO系统的使用。
lighttpd作者对fdevent系统封装相当的出彩,对于理解在C中使用面向对象的方式编程具有很好的帮助。
下一篇中将看一看fdevent系统的初始化和使用。
本文章由 http://www.wifidog.pro/2015/04/20/wifidog%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90lighttpd%E5%AF%B9%E5%A4%96%E6%8E%A5%E5%8F%A3.html 整理编辑,转载请注明出处