wifidog自带HTTP 服务器 Lighttpd1.4.20源码分析之array.c(h) -----通用数组(1)
Lighttpd提供了一个通用数组,这个数组与程序的其他部分练习较少,因此可以单独进行分析。
首先要说一下Lighttpd中的定义的一些数据结构。
在array.h中有下面的定义:
Code
typedef enum {
TYPE_UNSET, /* 数据的类型未设置,
这几种数据类型使用了面向对象的设计思想,
这个类型相当于父类型,继承关系见后面
*/
TYPE_STRING, /* 字符串类型 */
TYPE_COUNT, /* COUNT类型 */
TYPE_ARRAY, /* 数组类型 */
TYPE_INTEGER, /* 整数类型 */
TYPE_FASTCGI, /* FASTCGI类型 */
TYPE_CONFIG /* CONFIG类型 */
} data_type_t;
这是一个枚举类型,定义了各个数据类型的标志。从中可以看出程序中所定义使用的数据类型的种类和个数。
Lighttpd在定义数据类型的时候使用了面向对象的思想,因此,程序具有很好的扩展性和适应性。这些类型中,最重要的是UNSET类型,这个类型在所有的数据类型中,起到了父类型的作用。在array.h中,UNSET类型的定义如下:
Code
#define DATA_UNSET \
data_type_t type; \
buffer *key; \
int is_index_key; /* 1 if key is a array index */ \
struct data_unset *(*copy)(const struct data_unset *src); \
void (* free)(struct data_unset *p); \
void (* reset)(struct data_unset *p); \
int (*insert_dup)(struct data_unset *dst, struct data_unset *src); \
void (*print)(const struct data_unset *p, int depth)
typedef struct data_unset {
DATA_UNSET;
} data_unset;
其中,UNSET类型数据的定义中,数据的实际定义部分使用宏DATA_UNSET,这样可以方便其他类型在定义中直接引用DATA_UNSET宏来模拟继承。在宏DATA_UNSET中,定义了下面五个函数指针:
Code
struct data_unset *(*copy)(const struct data_unset *src);
void (* free)(struct data_unset *p);
void (* reset)(struct data_unset *p);
int (*insert_dup)(struct data_unset *dst, struct data_unset *src);
void (*print)(const struct data_unset *p, int depth)
这五个函数指针相当于UNSET的成员函数,其他类型可以通过对这五个指针赋值来实现成员函数的重写(Overwrite)。每种类型都配有自己特有的初始化函数,形式为:data_XXXXX *data_XXXXX_init(void)。在这些初始化函数中,对上面这五个函数指针进行赋值,当然,赋值的函数都应先定义好。
这几种类型的继承关系图如下:(类图)
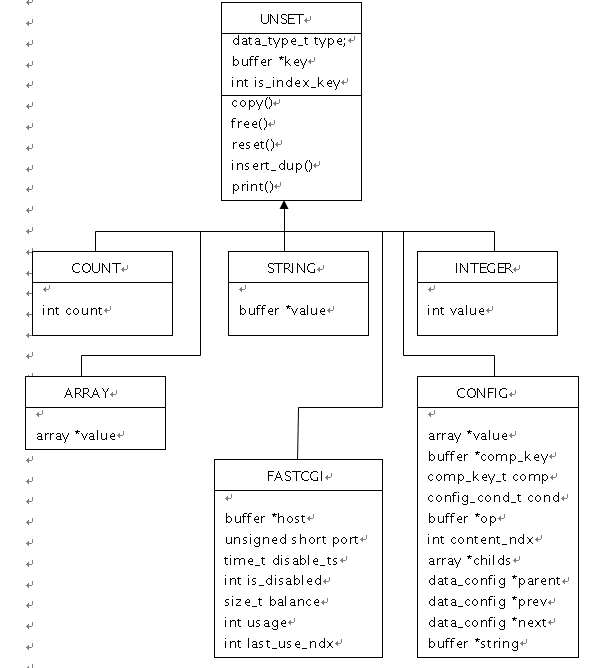
下面分析一下STRING类型的初始化函数data_string * data_string_init(void):
Code
data_string *data_string_init(void)
{
data_string *ds;
/*
分配内存空间。
这里用的是calloc函数,分配的空间会自动清零。
*/
ds = calloc(1, sizeof(*ds));
assert(ds);
/*
初始化各个数据成员,
这里调用buffer_init函数,主要就是分配内存空间
*/
ds->key = buffer_init();
ds->value = buffer_init();
/*确定成员函数的具体调用函数,对函数指针赋值*/
ds->copy = data_string_copy;
ds->free = data_string_free;
ds->reset = data_string_reset;
ds->insert_dup = data_string_insert_dup;
ds->print = data_string_print;
ds->type = TYPE_STRING;
return ds;
}
其他类型的init函数,以及其他函数都不难,读者可自行查看代码。
至于各个类型的用处以及各个类型中个成员变量的含义,暂且不用关心,只要知道这七个类型之间的关系即可,除了UNSET类型,其他类型的操作函数的实现都在文件data_XXXXX.c中。这些函数的实现都很简单,不在一一介绍,读者可自己看看。这七个类型构成了通用数组所要处理的类型,其中,在数组的定义和实现中只使用UNSET类型,利用上面的定义,通用数组可以不用关心数组中存储的到底是哪种具体的类型,只需将其按照UNSET类型来处理就可以了。这就实现了通用数组。
下面这个定义是通用数组的核心定义,也就是定义了数组。。。
Code
typedef struct
{
/* UNSET类型的指针型数组,存放数组中的元素 */
data_unset **data;
/* 存放着排好序的各个元素的下标的数组 */
size_t *sorted;
size_t used; /* data中使用了的长度,也就是数组中元素个数 */
/* data的大小。data的大小会根据数据的多少变化,会为以后的数据预先分
配空间 */
size_t size;
size_t unique_ndx; /* */
/* 比used大的最小的2的倍数。也就是离used最近的且比used大的2的倍
数 ,用于在数组中利用二分法查找元素*/
size_t next_power_of_2;
/* data is weakref, don't bother the data */
/* data就是一个指针,不用关系其所指向的内容 */
int is_weakref;
} array;
各个变量的含义见上。
array.h中还有一个定义:
typedef struct {
DATA_UNSET;
array *value;
} data_array;
本文章由 http://www.wifidog.pro/2015/04/13/wifidog-lighttpd%E5%88%86%E6%9E%90%E9%80%9A%E7%94%A8%E6%95%B0%E7%BB%84-1.html 整理编辑,转载请注明出处